Power BI予測精度を下げる5つのデータ品質問題

Power BI予測精度を下げる5つのデータ品質問題
「Power BIで予測機能を使ってみたが、結果がまったく現実とかけ離れている」――そんな経験をされた方は少なくないはずです。原因をアルゴリズムや設定の問題だと思いがちですが、実際には予測精度を下げる最大の要因はデータ品質にあることがほとんどです。
AIモデルの精度は提供されるデータの質に大きく依存しており、ノイズが多いデータをそのままAIに入力するとモデルは誤ったパターンを学習してしまい、予測や分類の精度が低下します。
本記事では、Power BIの予測分析に取り組む実務担当者が頻繁に陥る「5つのデータ品質問題」と、Power QueryおよびDAXを使ってそれぞれを整える具体的な対処法を解説します。予測機能を触る前に、ぜひこのチェックリストを確認してください。
目次
なぜ「モデルより先にデータを疑う」のか
Power BI Desktopの折れ線グラフには、クリック数回で予測線を描ける組み込みのフォーキャスト機能があります。
Power BIのデフォルト予測モデルは指数平滑法であり、データ内の周期性を自動検出して最適なモデルを当てはめます。季節性ありと判断すればETS AAA(ホルト・ウィンター法)、季節性なしならETS ANNモデルを内部で使い分けています。
このように仕組み自体は優秀です。しかし、データに欠損値や異常値がある場合は先にクリーニングし、不要な値を除外・修正しておく必要があり、日付列が連続しているかどうかのチェックも不可欠です。
問題はここにあります。機能がいくら高度でも、入力データに品質問題があれば出力は信頼できません。以降では「よくある5つの落とし穴」を具体的に見ていきます。
落とし穴① 日付の表記揺れ(西暦/和暦混在)
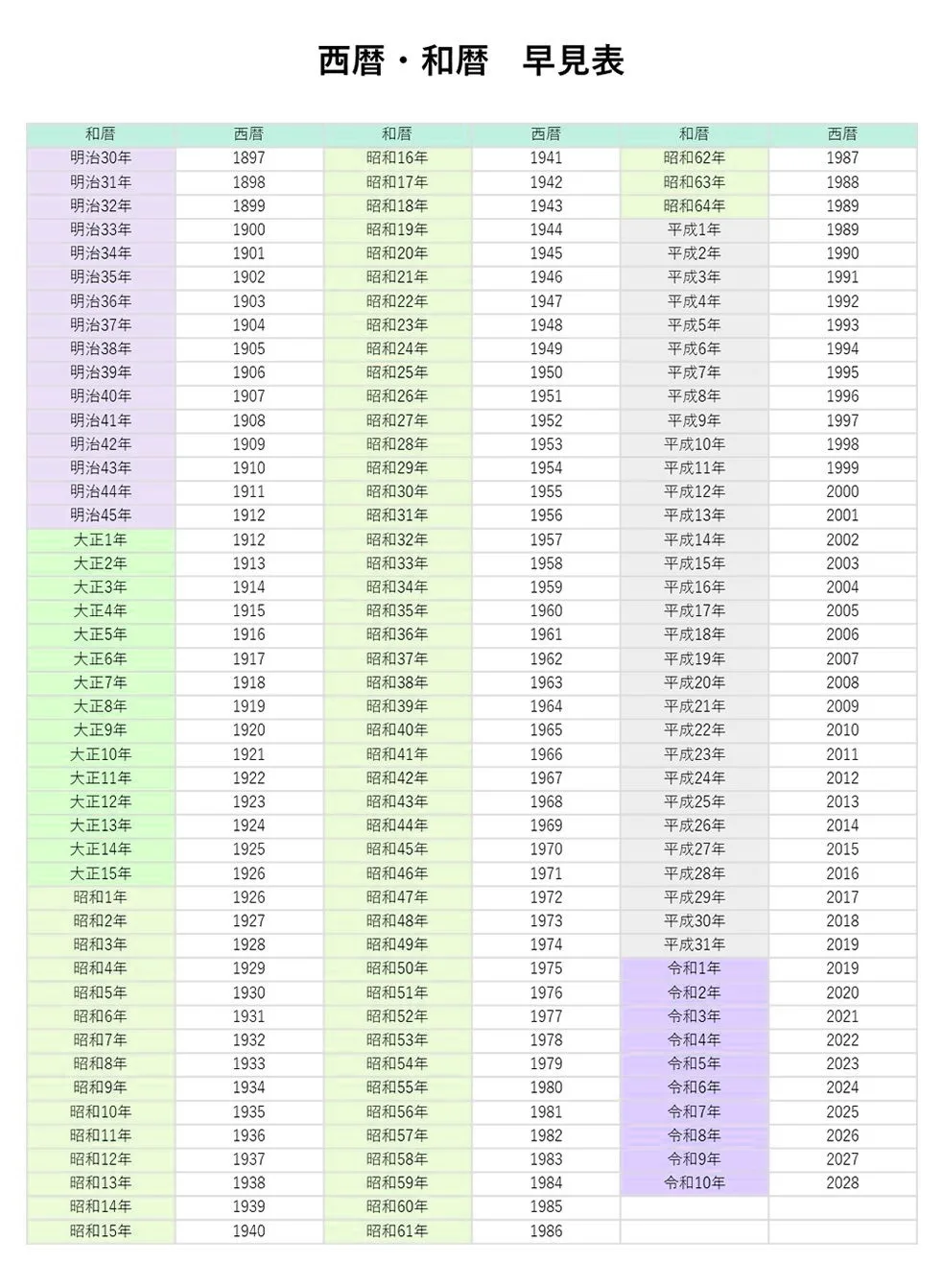
「令和3年4月」「R03/04」「2021/4」が同じ列に混在している」 ――これは日本企業のデータに特有の問題です。
「平成27年」「平17年」「H14」のように表記が統一されていない和暦が混在しているケースでは、元号の種類だけでなく表記方法までデータごとに変化していることがあり、さらに西暦で記されているデータも含まれる場合がある。
Power BIの予測機能は、日付列が一貫した連続データとして認識されることを前提にしています。
予測機能は軸にdate型のフィールドが1つあり、存在する値フィールドが1つだけという2つの条件が満たされている場合にのみ使用でき、ビジュアルが正しく構成されていないと予測セクションが使用できません。
表記が混在したままだとPower BIは日付列を文字列として認識し、時系列グラフすら正しく描けません。
対処法:Power Queryで一括正規化
データの表記を統一して「数値」として扱えるように加工する場合にもPower Queryが活用でき、ステップ形式で処理を進めていけるPower Queryなら、その場で処理方法を考えながら最終形に近づけていくことが可能です。
具体的な手順としては、Power Queryエディターで「値の置換」または「カスタム列」を使い、和暦の元号ごとに対応する年数オフセット(例:令和→+2018、平成→+1988)を加算して西暦に変換します。変換後は必ずデータ型を「日付型」に指定してください。
⚠ 注意点: 「令和元年」は「1年」と同義ですが、Excelで日付文字列に和暦の「元年」があるとき、DATEVALUE関数ではシリアル値に変換できないため、Power Queryでも「元年」表記があるとシリアル値に変換できない場合があるので、置換処理で「元年」を「1年」に変換するステップが必要です。
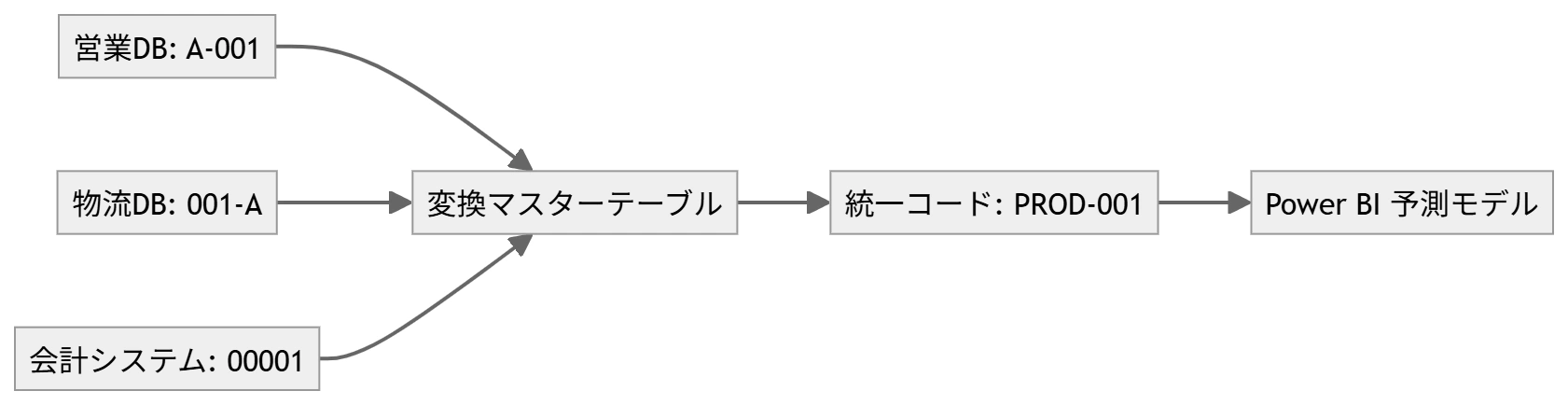
落とし穴② 商品コードが部門ごとに違う

営業部は「A-001」、物流部は「001-A」、会計システムは「00001」と、同じ商品を指す識別子が部門ごとに異なるケースです。
いくつものシステムや部門から集めたデータをまとめて使う際、ファイルの形式が異なっていたり、日付の書き方・単位が違う、文字コードが異なるなどの問題が混在していると、データを読み込む段階でエラーが続出し、想定外の時間とコストがかかってしまいます。前処理として表記ゆれをそろえたりカラム名やデータ型を標準化するといった作業が重要です。
予測分析では、たとえば「商品別の売上トレンド」を集計しようとしても、コードが統一されていなければ同じ商品のデータが別々に集計され、過去実績が分断されてしまいます。モデルには「A-001が急に売れ始めた新商品」と認識され、正しいトレンドが捉えられません。
対処法:DAXまたはPower Queryでマスターテーブルと結合
Power Query上で「コード変換マスターテーブル」を別途用意し、各部門コードを統一コードにマッピングするステップを追加します。この作業は一度行えば、以後のデータ更新時に自動で適用されます。DAXを使う場合は RELATED() 関数でリレーションシップ経由の名称統一も可能です。
落とし穴③ 過去データが2年分しかない
「データはあるが、Excelで管理し始めたのが2〜3年前」――こうした状況でも予測分析に踏み切ってしまうケースがあります。
タイムラインで予測する場合は、正確で安定した予測を生成するために、少なくとも2サイクル(年)のデータが必要になります。
(Microsoft Learning / PL-300公式ラボより)
これは最低ラインの要件です。季節性のある商材(例:夏冬で大きく動く消費財や、期末に集中する法人向けサービス)の場合、2年分では1サイクル分しか季節変動パターンを学習できず、信頼区間が広がって予測の実用性が著しく低下します。
Power BIのデフォルト予測モデルでは、季節性ありと判断すればホルト・ウィンター法を使いますが、データポイント数が1000以下である必要があり、大量データの場合サンプリングされ精度が落ちることもあります。
対処法:過去データの掘り起こしと欠損補完
まず、Excelファイルや旧システムの帳票など、デジタル化されていない過去データを優先的にインポートします。どうしても欠損が残る場合は、Power Query上で前後の平均値や移動平均で補完し、「何月のデータが欠けているか」をメモしておくことが重要です。
落とし穴④ イレギュラーデータが学習データに混入している
新型コロナウイルスの感染拡大期(2020〜2021年)や、大規模な特需・補助金終了に伴う駆け込み需要は、通常トレンドとは異なる強いシグナルを学習データに注入します。
予測の根拠とした前提条件が崩れると予想と違う結果が返ってくることがあり、他の人の予測データや外部パラメータを利用する時は予測の根拠を必ず確認することが重要です。
たとえば、2020〜2021年のコロナ禍のデータをそのまま学習させると、モデルはその急落または急騰を「通常の変動パターン」として学習します。その後の予測に、コロナ禍の異常値が尾を引き続けるのです。
対処法:Power Queryで異常期間を除外またはフラグ立て
Power Queryの「行のフィルタリング」で対象期間を除外するのが最もシンプルな方法です。ただし除外するとデータ数が減るため、別途「イレギュラーフラグ」列を追加して「0 = 通常期間 / 1 = 特殊期間」とし、DAXでフラグが0の期間のみを集計するメジャーを作成する方法も有効です。
💡 Tip:
折れ線グラフの分析メニューから「異常の検出」を有効化すると、系列の過去データから期待される範囲が算出され、その範囲を外れているポイントに異常マーカーが付き、他の関連するデータ項目との相関を調べて外れ値の要因を推測する機能があります。これを活用することで、どの時点がイレギュラーかを視覚的に特定できます。
折れ線グラフの分析メニューから「異常の検出」を有効化すると、系列の過去データから期待される範囲が算出され、その範囲を外れているポイントに異常マーカーが付き、他の関連するデータ項目との相関を調べて外れ値の要因を推測する機能があります。これを活用することで、どの時点がイレギュラーかを視覚的に特定できます。
落とし穴⑤ 目的変数の定義が曖昧
「売上」とひと口に言っても、税込か税別か、返品控除後か否か、計上タイミングが受注時か納品時か入金時か——これらが部門やシステムによって異なっていることがあります。
予測精度以前に、そもそも何を予測しているのかが曖昧なまま進んでいるケースです。
データ品質と量を確保することで、より信頼度の高い予測が可能になり、ビジネス活用を前提に「どのように意思決定や施策に結びつけるか」を意識して予測結果を解釈することが重要です。
目的変数の定義が曖昧なままだと、同じレポートを見た営業部と経営企画部が「数字が違う」と言い争う事態を招き、予測の信頼性が根本から揺らぎます。
対処法:メジャーの定義をDAXで一元管理
Power BIのデータモデル上で、「売上(税別・返品控除後・納品基準)」のように命名規則を統一したDAXメジャーをひとつだけ定義します。各部門がどの数字を使うべきかをレポート設計の段階で合意しておくことが、技術的な前処理と同等以上に重要です。
5つの落とし穴:チェックリスト
| # | 落とし穴 | 症状 | Power BI上の対処 |
|---|---|---|---|
| ① | 日付の表記揺れ | 日付列が文字列認識される / グラフが1点になる | Power Query で型変換・置換 |
| ② | 商品コードの不統一 | 同一商品が複数行に分断される | マスターテーブルとのリレーション |
| ③ | 過去データが2年未満 | 信頼区間が異常に広い | 既存データの掘り起こし・補完 |
| ④ | イレギュラーデータの混入 | 予測がコロナ禍・特需の影響を引きずる | 期間フィルター or 異常フラグ列 |
| ⑤ | 目的変数の定義が曖昧 | 「売上」の数字が部門ごとに違う | DAXメジャーで定義を一元化 |
表1: データ品質の5つの落とし穴と対処法
データを整えた後のステップ
5つの落とし穴を整理し終えたら、いよいよ予測機能の本格活用です。Power BI Desktopでは折れ線グラフの「分析」ペインから予測を追加でき、信頼区間(Confidence interval)は通常95%が一般的ですが、必要に応じて変更でき、数値が高いほど予測範囲が広がります。季節性は月次や四半期などに売上の波がある場合は手動で指定するか、Power BIに自動検知させる設定を活用できます。
さらに高度な予測を行いたい場合は、Azure Machine LearningとPower BIを連携させることも選択肢になります。
Azure MLは本格的な機械学習モデルの開発・運用プラットフォームであり、Power BIはAzure MLで構築・公開されたモデルをリアルタイム推論サービスとして呼び出し、その結果をレポートに取り込むことができます。
ただし、どれだけ高度な仕組みを使うとしても、今回紹介した5つのデータ品質問題が未解決である限り、予測精度は改善しません。まずはデータを整えることが最優先です。
まとめ
Power BIの予測精度を高めたいなら、まず「モデルの前にデータを疑う」という姿勢が欠かせません。本記事で紹介した5つの落とし穴――日付表記揺れ、商品コードの不統一、過去データ不足、イレギュラーデータの混入、目的変数の曖昧さ――は、Power QueryとDAXによるデータモデリングで体系的に解決できます。
一つ一つは地道な作業ですが、この「データの整え直し」を実施した後は、予測機能の精度が見違えるように向上します。

FAQ:Power BI予測分析のデータ品質でよくある疑問
Q1. Power BI 予測分析がうまくいかない主な原因は何ですか?
予測分析がうまくいかない主な原因は、アルゴリズムではなくデータ品質にあります。日付表記の揺れ(和暦・西暦混在)、商品コードの部門間不統一、過去データ期間の不足(2年未満)、コロナ禍などのイレギュラーデータの混入、目的変数の定義の曖昧さという5つの問題が代表的です。これらをPower QueryとDAXで整備してから予測機能を使うことで、精度が大きく改善します。
Q2. 日付表記の揺れは Power BI でどう修正できますか?
Power Queryの「値の置換」や「カスタム列」機能で和暦を西暦に一括変換できます。元号ごとにオフセット値(令和+2018、平成+1988など)を加算して西暦年に変換し、データ型を「日付型」に指定するのが基本手順です。「令和元年」など「元年」表記がある場合は、変換前に「元年→1年」への置換ステップを必ず追加してください。一度設定すれば、以後のデータ更新でも自動で適用されます。
Q3. Power BI の予測に必要な過去データは何年分ですか?
Microsoftの公式学習教材(PL-300ラボ)によれば、正確で安定した予測を生成するには少なくとも2サイクル(年)のデータが必要とされています。ただしこれは最低ラインであり、季節性の強い商材では3〜5年分あるとより信頼性が高まります。過去データが2年未満の場合、信頼区間が大きく広がり予測の実用性が著しく低下するため、旧システムやExcelファイルからの過去データ掘り起こしを先に行うことを推奨します。
Q4. コロナ特需など異常期間のデータはどう扱えばいいですか?
Power Queryの行フィルターで異常期間を除外するか、「イレギュラーフラグ」列を追加してDAXメジャーで通常期間のみを集計する方法が有効です。完全に除外するとデータ件数が減るリスクがあるため、フラグ方式のほうが柔軟に対応できます。また、Power BIの「異常の検出」機能を使えば、折れ線グラフ上で外れ値を自動マーキングし、どの期間が異常値かを視覚的に特定することも可能です。
Q5. 部門ごとに異なる商品コードを統合するにはどうすればよいですか?
Power Query上に「コード変換マスターテーブル」を用意し、各部門コードを統一コードにマッピングするのが最も確実な方法です。このマスターテーブルをPower BIのデータモデルでリレーション設定しておけば、データ更新のたびに自動で統一コードが適用されます。DAXの RELATED() 関数を使ってリレーション経由で製品名や分類を参照することもできます。マスターテーブルの管理は情報システム部門と営業・物流などのデータオーナー部門が共同で行う体制を作ることが重要です。
関連記事
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
データを起点に、課題の整理から施策の実行・運用定着まで一気通貫で伴走します。 流入〜CV・LTVといった指標をもとに、成果を妨げる要因を構造化し、現場で回せる手順と判断基準に落とし込める点が強みです。 様々な業界の幅広い現場で、担当者の負荷を減らしつつ成果につながる“仕組み化”を進めてきました。 承認の集中や情報の分散、手作業の繰り返しも整理し、AIエージェント/自動化まで落とし込み、少人数でも回り続ける運用を実現します。